|
|
Niveau : Intermédiaire Noel Rappin (noelrappin@gmail.com), Senior Software Engineer, Motorola, Inc. 23 Jan 2007
Dans cet article, vous installerez et configurerez votre base de données -- le back end de votre application Web -- créerez un schéma de base de données, et apprendrez quelques outils simples pour remplir les données. La base de données que vous emploierez est Apache Derby, une base de données relationnelle 100% pure de Java™ qui a été à l'origine développée sous le nom de Cloudscape™. Par la suite, le code de Cloudscape a été acquis par IBM®, qui a donné une version open source dans le projet d'Apache. Le même projet est également distribué par Sun Microsystems sous le nom de JavaDB. J'ai choisi Derby pas simplement parce que j'aime le fait qu'il a trois noms, mais parce qu'il est léger et facile de configurer. À la différence de la plupart des bases de données relationnelles, Derby peut fonctionner dans la même machine virtuelle de Java (JVM) cans le votre code Java côté serveur. (Vous pouvez également l'exécuter dans une JVM séparé si vous préférez.) Cela facilite le développement et le déploiement, et Derby est suffisament rapidement pour être un choix raisonnable pour d'application Web de taille petite à moyenne. Avant que vous commenciez, quelques notes : D'abord, pour suivre cet article, vous devriez avoir une notion des bases de données relationnelles, du JDBC, et du langage d'interrogation structuré (SQL). En second lieu, cet article présente quelques choses dans le code pour la démonstration qui ne sont pas susceptibles d'être idéale dans un système de production. J'essaye d'expliquer ces points tout au long du tutoriel, mais je ne parle pas de l'optimisation des performances. If you aren't, you can grab whichever other distribution meets your needs. One distribution is only the library files, another is the library and documentation, one distribution is the library with debug information, and one distribution is just source code. Derby is based exclusively on Java technology and will run on any JVM version 1.3 or later. The code examples here assume that you're using Java 1.4. Derby est disponible en tant qu'élément du projet de DB d'Apache. En date de cette écriture, la version en cours est version 10.1.3.1. Si vous allez travailler dans l'environnement de développement intégré par Eclipse (IDE), c'est suffisant récupérer les deux plugins : Si vous n'employez pas Eclipse, extraire la distribution que vous avez téléchargée n'importe où cela vous convient. Quand cela est fait, s'assurer que les fichiers lib/derby.jar et lib/derbytools.jar sont dans votre variable Si vous employez Eclipse, l'installation pour le développement est un peu plus facile. Pour activer Derby dans Eclipse, accomplissez ces étapes :
La figure 1 montre le menu de Derby après que vous ayez ajouté la nature de Derby. Figure 1. Le menu Derby dans Eclipse 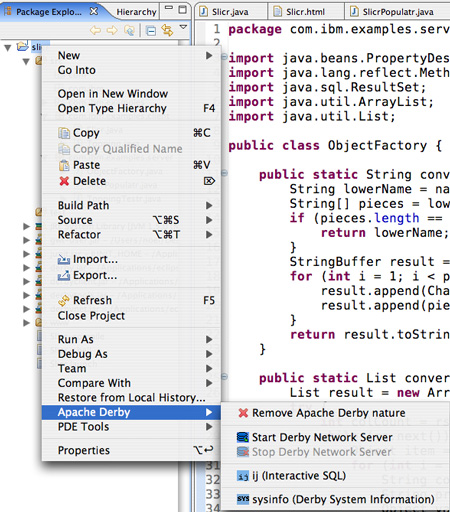
Même si vous employez l'éclipse pour le développement, vous devez avoir les fichiers JAR appropriés et disponibles quand vous déployez votre application. Je couvrirai ceci plus en détail dans un article utltérieur. Avant que vous commenciez à utiliser votre base de données, prenez une minute pour déterminer ce que la base de données devrait gérer. Je n'ai pas encore discuté des conditions pour l'application de Slicr, ainsi supposons que vous voulez que la base de données puisse stocker les informations basiques du client et de l'ordre de commande. S'occuper de la base de données dans les premières étapes est pour la maintenir facilement et utiliser quelques fonctionnalités spécifiques de la base de données, même si cela signifie pour commencer d'ajoutert du traitement additionnel dans votre code Java. Une base de données est une grande dépendance tierce, et vous devez vous protéger contre avoir des décisions au sujet de la de base de données qui commanderaient le reste de votre application. Vous voulez réduire au minimum les points de contact entre votre programme et la base de données de sorte que si vous changez en certain point les systèmes, le changement (portage) soit réellement faisable. La rapidité est que la principale des choses qu'il vous suffira pour améliorer l'exécution de base de données tendent à vous attacher à employer un système spécifique, ainsi essayez de reporter cette optimisation jusqu'au dernier moment possible dans le projet. Le début de votre conception de base de données est franc. Ordres de place de clients. Les ordres se composent d'une ou plusieurs pizzas (pour le moment, ignorer que le restaurant peut vendre d'autre nourriture). Une pizza se compose de zéro garniture ou plus, qui pourraient être sur la moitié de la pizza ou sur toute la pizza. En ce moment, inquiétez vous seulement qu'il y ait suffisament d'information au sujet du client pour pouvoir le livrer et confirmer les ordres de commande, comme montre la liste 1. Liste 1. La table du client (customers)
Le rapport d'état (statement) id int generated always as identityL'autre option pour une colonne d'identité serait : generate by default as identityLa différence est que Vous voulez toujours avoir un ID dans la base de données qui est complètement sans raccordement à une valeur réelle. Quelqu'un sur votre équipe essayera par la suite de vous convaincre que vous pouvez employer quelque chose comme un nombre de téléphone comme clef, parce qu'elle identifiera également uniquement un client. Ne pas la faire. La dernière chose que vous avez auriez à faire est de mettre à jour votre base de données entière parce que quelqu'un a déplacé et a changé les numéros de téléphone. Créer la table des ordres de commande Pour la table d'ordre (voir la liste 2), vous voulez juste l'attacher à un client et à une date et tenir compte d'un escompte. Vous pouvez calculer le reste du prix en code. Liste 2. La table des ordres de commande (orders)
En plus de la clef primaire Le dernier problème de conception de base de données est la pizza et les garnitures. Bien, pas les garnitures; c'est assez simple, comme le montre la liste 3. Lise 3. La table des garnitures (toppings)
The question is, how do you manage the relationship between pizza and toppings?
A pizza is an order, a size, and a set of toppings. Classic database
normalization would say to create a Pizza table, and then a many-to-many
table relating pizza IDs to topping IDs. Doing so has many nice properties,
among them the fact that it allows an infinite number of toppings on a pizza.
However, managing the database relationship between the tables can have a
performance cost. If infinite toppings aren't needed, you can include several
topping fields in the Pizza table ( La question est, comment contrôlez-vous le rapport entre la pizza et les garnitures ? Une pizza est un ordre, une taille, et un ensemble de garnitures. La normalisation classique de base de données indiquerait de créer une table de pizza, et puis une table multiple reliant des identifications de pizza (IDs) aux identifications de garniture (IDs). Faire ainsi a beaucoup de propriétés gentilles, parmi elles le fait qu'il permet un nombre infini de garniture sur une pizza. Cependant, la gestion du rapport de base de données entre les tables peut avoir un coût d'exécution. Si les garnitures infinis ne sont pas nécessaires, vous pouvez inclure plusieurs champs de garnitures dans la table Pizza (topping_1, topping_2, et ainsi de suite). Conceptuellement, c'est un peu plus simple, mais ca la rendrait plus maladroites par exemple pour compter les garnitures les plus populaires. Si vous vous sentez particulièrement aventureux, vous pourriez avoir un simple champs de garnitures et le peupler avec un bitmap ou une chaine concaténée ou analogue. Je vous le déconseille fortement. Après une petite reflexion, j'ai décidé d'aller de pair avec la forme entièrement normale. Vous voudriez laisser autant de garnitures que voulu sur une pizza, car la mise des garnitures dans la même table deviendrait plutôt laide. Ainsi, utilisez le code montré dans la liste 4. Liste 4. La tables des pizzas
Juste pour être clair, vous aurez les tailles 1, 2, 3, et 4 représentant respectivement petite, moyenne, grande, et ultra-large. Le placement des garnitures sera -1, 0, ou 1 pour demi gauche, pizza entière, et la moitié droite, respectivement. Et vous avez besoin d'un ID séparée pour chaque partie de la pizza, de sorte que vous puissiez par exemple tenir compte des pepperoni supplémentaires en prenant des pepperoni comme garnitures apparaissant deux fois dans la même pizza. Note : Est-ce que j'ai mentionné que tous ces noms que vous avez mis après Cela devrait le faire pour votre schéma de base de données. Maintenant vous pouvez l'entrer dans la base de données. Vous avez un schéma; maintenant vous le créer et y insèrer quelques données initiales. Vous allez créer un petit programme autonome qui exécute cette installation. Cepedant ce n'est pas la seule méthode possible. Vous pourriez employer la ligne de commande d' Vous commencez par quelques données assez statiques -- la liste des garnitures de pizza ce que vous avez inclus dans la page de Slicr dans la partie 1. Encore, cette approche fonctionne la plupart du temps parce que vous insérez des données statiques. Vous établirez une table de garnitures en laquelle chaque garniture a un nom et un prix de base. Le code montré dans la liste 5 établit ces données. Pour le moment, supposer que toutes les garnitures ont le même prix. Liste 5. Activer la table des granitures dans Derby
Si vous connaissez JDBC, la majeure partie de ce code sera familière. Cependant, il y a des couples des fonctionnalités à spécifiques Derby que je devrais couvrir. Vous commencez par charger la classe pilote en utilisant l'idiome de jdbc:derby:database name;[attr=value]Le nom de base de données est le nom que vous voulez employer pour se référer à votre base de données. Il n'importe pas beaucoup ce que vous avez sélectionnez tant que vous vous y êtes conformé quand vous ouvrez la base de données toujours depuis votre code de serveur. Après que vous créiez la connexion, vous êtes dans le standard de JDBC. Vous créez un Le code de SQL dans les Avant que le programme existe, vous faites un appel spécial pour obtenir une connexion avec l'URL Après avoir exécuté ce petit programme, vous verrez un dossier à la racine de votre application appelé derbyDb. Ce dossier stocke les fichiers binaires dans lesquels Derby stocke ses données. Ne changer pas ces fichiers sous aucun prétexte. Préparer les données pour for GWT What makes a serializable field? First, the field can be of a type that implements
Votre schéma de base de données etant en place et les données statiques étant chargé, maintenant vous devez définir comment vous allez communiquer ces données à votre client et vice-versa. Par la suite, vous allez devoir arranger des données en série (serialize) à travers la connexion client-serveur. Pour que cette sérialisation fonctionne, vos classes de données certaines doivent être où GWT peut les voir et les traiter, qui signifie que les classes doivent être définies dans votre paquet Il y a quelques restrictions additionnelles à une classe de client qui va être sérialisée. Déjà, la classe doit implémenter l'interface
Que fait un champ serializable ? D'abord, le champ peut être d'un type qui implémente Liste 6. Un champ et et une méthode sérialisable
Note : L'argument dans une liste de méthode doit indiqué ses types dans le commentaire, contrairement à la valeur de retour. Noter que quelque toute chose à faire avec java.sql et le JDBC est absent de cette liste d'objets serializable. Peut importe ce que vous fassiez pour obtenir de votre jeu de données vous devez le faire dans me code côté serveur. En ce moment, vous entrez dans le monde de l'Object-Relational Mapping (ORM), ou transférer des données depuis une structure de base de données relationnelle à votre programme Java, une structure orientée object. Pour un système de production complexe Java, vous voulez probablement employer un système préexistant et véritable d'ORM, tel que Hibernate ou Castor. Tous les deux systèmes chargent automatiquement vos données de la base de données dans des objets Java de votre choix. Cependant, ils exigent également une grosse configuration avant que vous obteniez commencé. Dans l'intérêt de se concentrer sur Derby et GWT ici, je présente un convertisseur rapide qui sert pendant le début du développement. Par la suite, vous pouvez le permuter pour un outil plus puissant. D'abord, créer les classes d'haricot (bean classes) pour toutes vos tables de données. J'emploie la classe Listing 7. La classe Topping
L'outil simple d'ORM est indiqué dans la liste 8. Liste 8. Simple ORM tool
La méthode
Le code va plus loing que vous pourriez penser. Vous pouvez executer avec lui tout de suite sur n'importe quel outil de base de données sans davantage de configuration. Vous n'avez pas besoin de maintenir un fichier synchronisé avec votre base de données pendant la phase de développement, quand vous changerez votre schéma. Et il ne sera pas difficile de permuter sur un outil plus puissant dans quand le moment sera venu. La liste 9 présente cet outil dans l'action, relistant tous l'exemple de l'instance Liste 9. Essayer l'outil ORM
Ce programme d'essai crée une connexion à Derby sur la base de données de Slicr. (Vous n'aurez plus a vous demander plus l'URL duprotocole pour créer la base de données si nécessaire.) Vous exécutez une simple question SQL, et puis passez les résultats à votre usine (factory). Alors vous êtes libre de faire une boucle sur la liste résultatante et de quitter la base de données. Your database is now installed and configured. You created a database schema and discovered some simple tools for putting data into it. After two articles in this series, your Slicr project now has simple but functional front and back ends. The next step is communication. In the third article in this series, you'll learn about the framework that GWT uses to make Remote Procedure Calls (RPCs) easy to code and manage. Votre base de données est maintenant installée et configurée. Vous avez créé un schéma de base de données et avez découvert quelques outils simples pour y mettre des données. Après deux articles de cette série, votre projet de Slicr a maintenant les extrémités avant (front end) et arrières (back end) simples mais fonctionnelles. La prochaine étape est le communication. Dans le troisième article de cette série, vous apprendrez l'utilisation du cadre (framework) GWT pour faire de la procédure d'appel distant (RPCs) facile à coder et contrôler. Article traduit en Français
Original English article
Learn
Get products and technologies
Discuss
| |||||||||||||||||||||||||||||||||||||